

问题背景:模块A内部有一块RAM作为内部状态信息缓存,这个信息一方面需要被内部逻辑进行读写,一方面又需要被外部CPU总线读写,此时已经在模块A中分了时隙用于同时处理两个接口访问。现在模块B也需要对模块A中的RAM进行访问,并且优先级比CPU总线要高,因为外部CPU访问没那么紧急,都是可以挂起等待的。这个时候如果再额外增加一组总线用于连接模块A和模块B,那处理逻辑是很复杂的,所以我们可以复用CPU总线,在外部CPU和模块A之间新增一个模块用于接管这个总线并且进行调度,保证模块B一定是高优先级访问,在B模块读写时屏蔽外部的CPU信号。
一、问题简化描述
1)外部CPU访问接口
/*
* Filename: /home/ssy/Code/hdl/MIBR/A
* Path: /home/ssy/Code/hdl/MIBR
* Created Date: Thursday, December 4th 2025, 12:05:43 am
* Author: Shirainbown
*
* Copyright (c) 2025 Non Inc.
*/
module A#(
parameter ADDR_WIDTH = 2,
parameter DATA_WIDTH = 2
)
(
input clk,
input rst_n,
input cpu_wr,
input [ADDR_WIDTH -1 :0] cpu_waddr,
input [DATA_WIDTH -1 :0] cpu_datain,
input cpu_rd,
input [ADDR_WIDTH -1 :0] cpu_raddr,
output reg [DATA_WIDTH -1 :0] cpu_dataout,
output reg cpu_rd_ack,
output reg cpu_wr_ack
);
localparam REG_NUM = 1 << ADDR_WIDTH;
localparam ACK_DELAY = 10;
reg [DATA_WIDTH-1:0] reg_file [0:REG_NUM-1];
reg [ACK_DELAY-1 :0] rd_in;
reg [ACK_DELAY-1 :0] wr_in;
always @(posedge clk ) begin
if (rst_n == 1'd0) begin
rd_in <= {(ACK_DELAY){1'd0}};
wr_in <= {(ACK_DELAY){1'd0}};
end
else begin
rd_in <= {rd_in[ACK_DELAY-2:0],cpu_rd};
wr_in <= {wr_in[ACK_DELAY-2:0],cpu_wr};
end
end
integer i;
always @(posedge clk ) begin
if (rst_n == 1'd0) begin
for (i = 0; i < REG_NUM; i = i + 1)
reg_file[i] <= i;
cpu_wr_ack <= 1'b0;
end
else begin
if (cpu_wr) begin
reg_file[cpu_waddr] <= cpu_datain;
cpu_wr_ack <= ~wr_in[ACK_DELAY-1] & wr_in[ACK_DELAY-2]; // 写完成应答(ACK_DELAY 拍延迟)
end
else begin
reg_file <= reg_file;
cpu_wr_ack <= 1'b0;
end
end
end
always @(posedge clk ) begin
if ( ~rd_in[ACK_DELAY-1] & rd_in[ACK_DELAY-2]) begin
cpu_dataout = reg_file[cpu_raddr];
cpu_rd_ack = 1'b1;
end
else begin
cpu_dataout = {DATA_WIDTH{1'b0}};
cpu_rd_ack = 1'b0;
end
end
endmodule时序图大致为(通常ack传回cpu会消耗clk,所以cpu_wr不是立刻拉低):

2)高优先级周期性访问接口
假设高优先级的端口需要周期性上报模块A中的寄存器(一共4个),满足以下规则:

每32拍读一次,一次读取一个寄存器
从0到3轮询读取item
读完一轮之后由参数GAP控制下一次读取
需要完全保证读出数据能够稳定上送,不被外部CPU访问影响。
3)具有超时告警的外部CPU访问模块
通常外部CPU访问接口长时间没有得到ack之后会拉起告警信号,防止CPU挂死。这里假设CPU从拉高rd或者wr信号之后,需要在32个周期内得到ack,否则会上报告警,示意图如下:

/*
# ------------------------------------
# File: /home/ssy/Code/hdl/MIBR/cpu_access.v
# Project: /home/ssy/Code/hdl/MIBR
# Created Date: Thursday, December 4th 2025, 12:20:11 am
# Author: Shirainbown
# -----
# Module: cpu_access.v
# -----
# Description:
# -----
# Copyright (c) 2025 Non Inc.
# ------------------------------------
*/
module cpu_access #(
parameter DATA_WIDTH = 2,
parameter ADDR_WDITH = 2
)
(
input wire clk,
input wire rst_n,
output wire cpu_rd, // CPU 发起读请求(高有效)
output reg cpu_wr, // CPU 发起写请求(高有效)
output reg [ADDR_WDITH-1:0]cpu_raddr, // CPU 发起写请求(高有效)
input wire cpu_rd_ack, // 外设返回的读应答(可以和 wr_ack 共用一个也行)
input wire cpu_wr_ack, // 外设返回的写应答
input wire [DATA_WIDTH-1:0]cpu_rd_data,
output reg cpu_timeout // 超时告警,保持到本次访问结束
);
reg [5:0] cnt64 ;
reg cpu_rd_0d;
reg cpu_rd_1d;
reg cpu_rd_2d;
assign cpu_rd = cpu_rd_2d;
always @(posedge clk ) begin
if (rst_n == 1'd0) begin
cnt64 <= 6'd0;
cpu_rd_0d <= 1'd0;
cpu_rd_1d <= 1'd0;
cpu_rd_2d <= 1'd0;
cpu_wr <= 1'd0;
cpu_raddr <= 'd0;
end
else begin
cnt64 <= cnt64 >= 58 ? 6'd0 : 6'd1 + cnt64;
cpu_rd_0d <= cpu_rd_ack == 1'd1 ? 1'd0 : cnt64 == 6'd0 ? 1'd1 : cpu_rd_0d;
cpu_rd_2d <= cpu_rd_1d;
cpu_rd_1d <= cpu_rd_0d;
cpu_raddr <= cpu_rd_ack == 1'd1 ? cpu_raddr +'d1 :cpu_raddr;
end
end
// 合并读写请求,只要有任意一个有效就启动计时
wire cpu_req = cpu_rd | cpu_wr;
wire cpu_ack = cpu_rd ? cpu_rd_ack : cpu_wr_ack; // 对应请求的 ack
reg [5:0] cnt; // 0~63,足够计 32 个周期
reg timeout_pending;
always @(posedge clk ) begin
if (!rst_n) begin
cnt <= 6'd0;
cpu_timeout <= 1'b0;
timeout_pending <= 1'b0;
end
else begin
// 1. 请求到来(上升沿)时清零计数器,开始计时
if (cpu_req && !(|cnt)) begin // 检测到新的请求(之前计数器为0)
cnt <= 6'd1; // 从 1 开始计数,避免立即为0的情况
timeout_pending <= 1'b0;
cpu_timeout <= 1'b0;
end
// 2. 正在计时且没有收到 ack
else if (|cnt && !cpu_ack) begin
if (cnt < 6'd32)
cnt <= cnt + 1'b1;
else begin
// 到达 32 个周期仍无 ack → 触发超时
timeout_pending <= 1'b1;
cpu_timeout <= 1'b1;
end
end
// 3. 收到 ack,立即清除超时(即使已经超时也要清)
if (cpu_ack) begin
cnt <= 6'd0;
timeout_pending <= 1'b0;
cpu_timeout <= 1'b0;
end
// 4. 请求结束(req 拉低)时,如果之前超时了,也要清掉 timeout
// (防止下次请求一来又误认为超时)
if (!cpu_req) begin
cnt <= 6'd0;
cpu_timeout <= timeout_pending ? 1'b1 : 1'b0; // 保持到请求结束
end
end
end
endmodule二、问题分析
本质上,CPU_ACCESS模块和HIGH_PRI模块都是为了获取A中的寄存器数据,需要增加一个仲裁功能,能够作为MUX来选择当前时刻到底A连接的是CPU_ACCESS还是HIGH_PRI中的读逻辑。可以直接将HIGH_PRI模块放在二者之间,当HIGH_PRI需要访问寄存器的时候就屏蔽来自CPU_ACCESS的请求,等待读取完成后再释放总线。
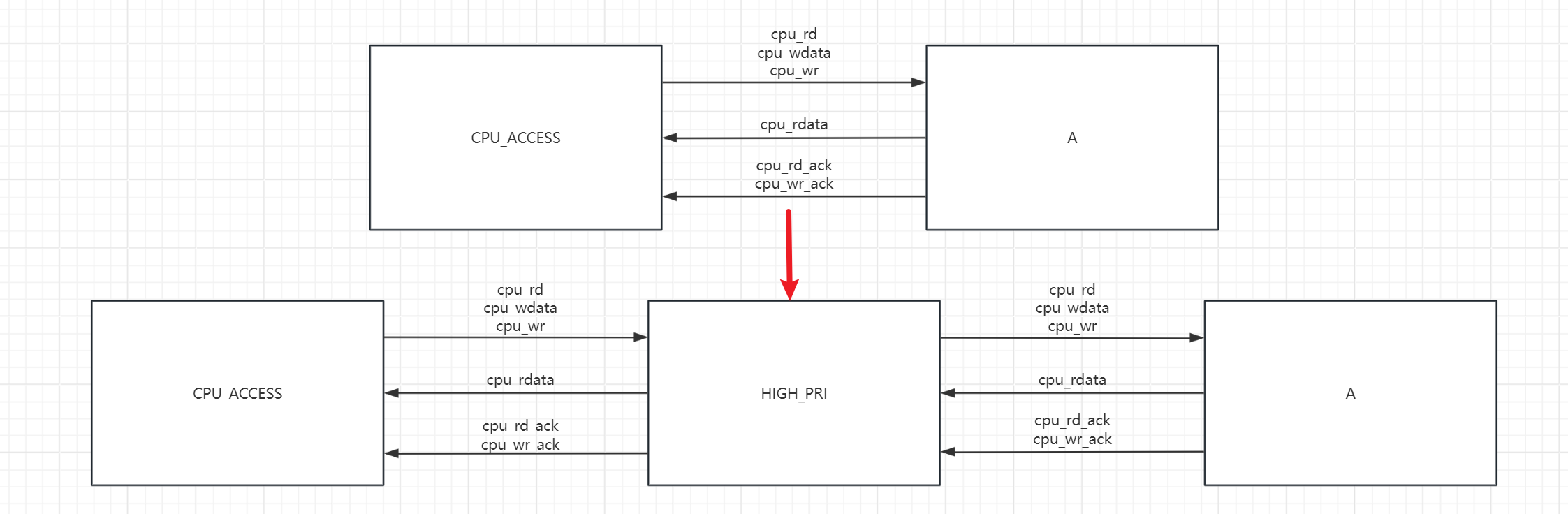
一个想法是将整个HIGH_PRI上报周期都给HIGH_PRI模块,外部CPU访问放在两次轮询之间,如下图红色区间:

但是这样会导致外部CPU访问超时,因此必须得将外部CPU访问插入到每个item之间。
那么需要考虑以下几个问题:
在一次上报期间,item之间的上报间隔为32拍,那么就要求读请求访问间隔为32拍。那么外部CPU访问时间段放置在哪?
如何保证外部CPU和HIGH_PRI之间的ack不会串通道,比如base_time处应当由HIGH_PRI读item,但是如果在base_time之前外部CPU正在读且将要返回ack,此时HIGH_PRI会获取到这个ack以及错误的读数据。
A模块里面是获取cpu_rd的上升沿的,如果HIGH_PRI和CPU_ACCESS的在切换控制权时,cpu_rd始终保持高,会导致A模块不能正确返回ack。
针对上面几个问题我们得到下面的访问时隙分配:
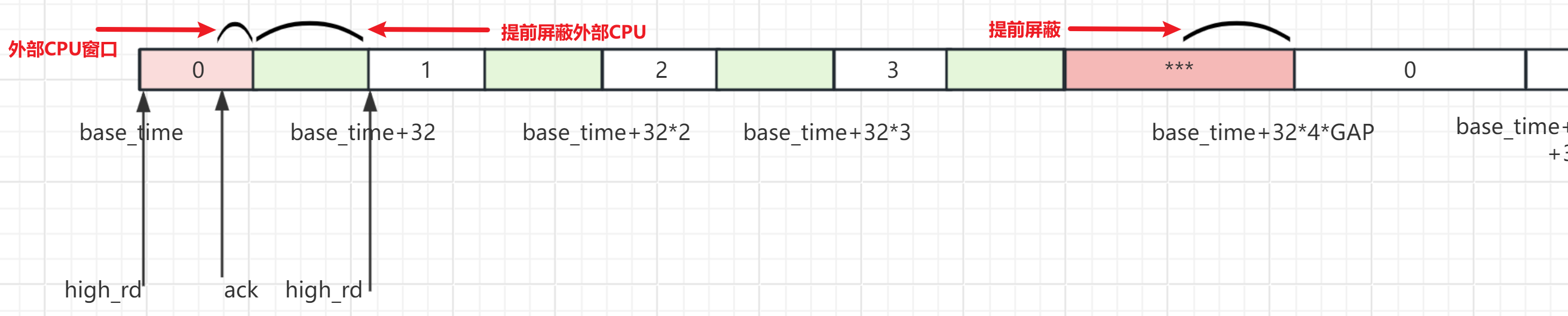
每个base_time需要发起高优先级的rd,那么需要提前屏蔽外部的CPU请求(绿色窗口),保证返回的ack和当前高优先级请求对应。那么外部CPU访问窗口,放在高优先级ack返回后到提前屏蔽之间,如果这个期间有外部CPU访问请求,那么后面跟着的绿色窗口能够保证外部CPU能够返回ack。这样可以保证在下一次高优先级rd发起时,外部CPU是空闲的,不会串ack。
为什么说这里是分优先级的?
HIGH_PRI 模块读取A中寄存器是固定周期的,CPU_ACCESS是随机,要求是HIGH_PRI读的时候,CPU_ACCESS等待。
如果平级应该怎么做?
如果平级那就分为两个时隙,两个时隙均只相应对应的访问请求,完成一次请求之后释放总线给另一个接口。
三、代码实现
先给出一个简易的结构框图:
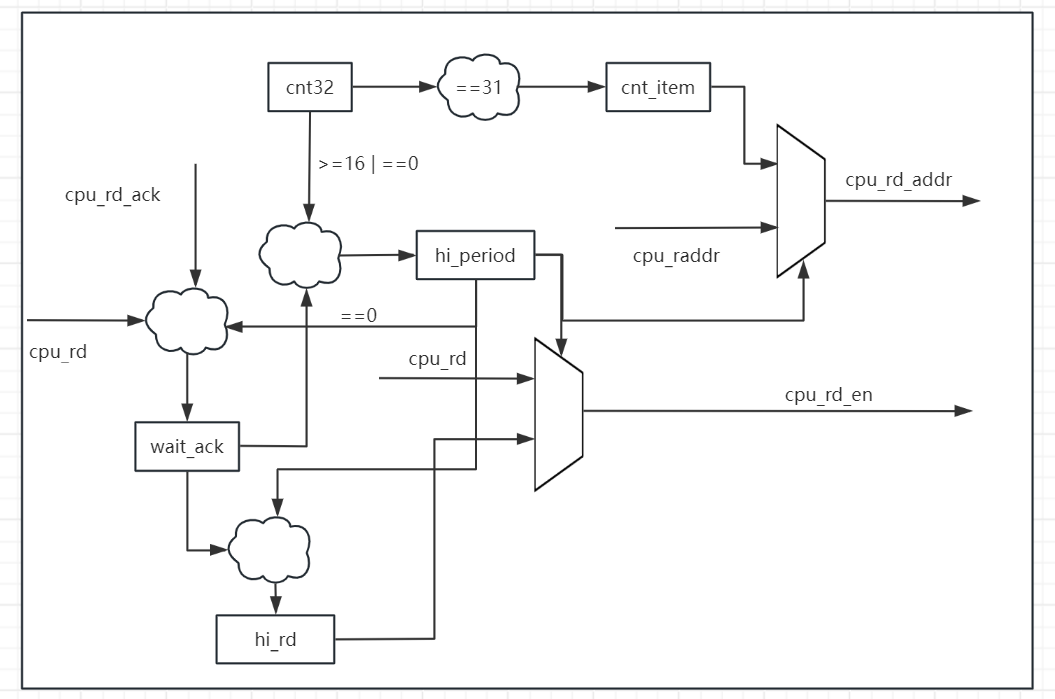
1、hi_period 用于指示当前是否处于屏蔽状态,刚进入base_time(cnt32==0)或者cnt32>=16时,如果没有外部CPU访问则拉高。
2、hi_period 拉高时,通过MUX接管所有的CPU相关的信号。
3、wait_ack 表示在非接管期间,接收到了来自外部的CPU请求,需要等待ack返回后才能进入hi_period 。
/*
# ------------------------------------
# File: /home/ssy/Code/hdl/MIBR/high_pri.v
# Project: /home/ssy/Code/hdl/MIBR
# Created Date: Thursday, December 4th 2025, 1:01:13 pm
# Author: Shirainbown
# -----
# Module: high_pri.v
# -----
# Description:
# -----
# Copyright (c) 2025 Non Inc.
# ------------------------------------
*/
//为了简化,这里不处理cpu_wr的请求,不考虑中间GAP,直接轮询
module high_pri
#(
parameter ADDR_WIDTH = 2,
parameter DATA_WIDTH = 2
)
(
input wire clk,
input wire rst_n,
input wire i_cpu_rd,
input wire i_cpu_rd_ack,
input wire [ADDR_WIDTH-1:0] i_cpu_raddr,
input wire [DATA_WIDTH-1:0] i_cpu_rdata,
output wire [DATA_WIDTH-1:0] o_cpu_rdata,
output wire [ADDR_WIDTH-1:0] o_cpu_raddr,
output wire o_cpu_rd,
output wire o_cpu_rd_ack,
output wire o_mibr_ack,
output wire [DATA_WIDTH-1:0] o_mibr_rdata
);
//localparam GAP = 1;
//reg [GAP-1:0] cnt_gap;
reg [4:0] cnt32;
reg [ADDR_WIDTH-1:0] cnt_item;
reg hi_period;
reg wait_ack;
reg hi_rd;
reg hi_rd_d;
always @(posedge clk ) begin
if (!rst_n) begin
cnt32 <= 5'd0;
cnt_item <= {ADDR_WIDTH{1'd0}};
end
else begin
cnt32 <= cnt32+ 5'd1;
cnt_item <= cnt32 == 5'd31 ? cnt_item +1 : cnt_item;
end
end
always @(posedge clk ) begin
if (!rst_n) begin
hi_period <= 1'd1;
end
else begin
if(hi_period == 1'd0)begin
if(wait_ack == 1'd1)begin
hi_period <= cnt32 >= 5'd16 && i_cpu_rd_ack == 1'd1 ? 1'd1 : 1'd0;
end
else begin
hi_period <= cnt32 >= 5'd16;//cnt32 == 5'd0 || cnt32 >= 5'd16;
end
end
else
hi_period <= i_cpu_rd_ack == 1'd1 ? 1'd0 : hi_period;
end
end
always @(posedge clk ) begin
if (!rst_n) begin
hi_rd<= 1'd0;
hi_rd_d<= 1'd0;
end
else begin
hi_rd_d <= hi_rd;
if(hi_period == 1'd1 && cnt32 <=5'd1)begin
hi_rd <= 1'd1;
end
else begin
hi_rd <= hi_rd == 1'd1 ? i_cpu_rd_ack == 1'd1 ? 1'd0 : 1'd1
:1'd0;
end
end
end
always @(posedge clk ) begin
if (!rst_n) begin
wait_ack <= 1'd0;
end
else begin
if(wait_ack == 1'd0)
if(hi_period == 1'd0)
wait_ack <= i_cpu_rd == 1'd1 ? 1'd1: 1'd0;
else
wait_ack <= 1'd0;
else
wait_ack <= i_cpu_rd_ack == 1'd1 ? 1'd0 : wait_ack;
end
end
assign o_cpu_rdata = i_cpu_rdata;
assign o_cpu_rd = hi_period == 1'd1 ? hi_rd : i_cpu_rd & ~hi_rd_d;
assign o_cpu_rd_ack = hi_period == 1'd1 ? 1'd0 : i_cpu_rd_ack;
assign o_cpu_raddr = hi_period == 1'd1 ? cnt_item : i_cpu_raddr;
assign o_mibr_ack = hi_period == 1'd1 ? i_cpu_rd_ack : 1'd0;
assign o_mibr_rdata = hi_period == 1'd1 ? i_cpu_rdata : 'hf;
endmodule
简单写一个testbench看一下效果:
/*
* Filename: /home/ssy/Code/hdl/MIBR/top
* Path: /home/ssy/Code/hdl/MIBR
* Created Date: Thursday, December 4th 2025, 12:06:23 am
* Author: Shirainbown
*
* Copyright (c) 2025 Non Inc.
*/
module top();
localparam DATA_WIDTH = 2;
localparam ADDR_WDITH = 2;
wire [DATA_WIDTH -1 :0] a_rdata;
wire [DATA_WIDTH -1 :0] o_mibr_to_cpurdata;
wire [ADDR_WDITH -1 :0] a_raddr;
wire [ADDR_WDITH -1 :0] o_mibr_to_raddr;
wire high_to_A_rd;
wire high_to_cpu_ack;
reg clk = 0;
reg rst_n = 0;
always #5 clk = ~clk;
wire cpu_rd_A;
wire A_rdack_cpu;
initial begin
#50;
rst_n = 1;
#5000;
$finish;
end
initial begin
$fsdbDumpfile("top.fsdb");
$fsdbDumpvars(0,top);
$fsdbDumpMDA();
end
A #(
.DATA_WIDTH(DATA_WIDTH),
.ADDR_WDITH(ADDR_WDITH)
)instA
(
.clk (clk),
.rst_n (rst_n),
.cpu_wr (),
.cpu_waddr (),
.cpu_datain (),
.cpu_rd (high_to_A_rd),
.cpu_raddr (o_mibr_to_raddr),
.cpu_dataout (a_rdata),
.cpu_rd_ack (A_rdack_cpu),
.cpu_wr_ack ()
);
cpu_access #(
.DATA_WIDTH(DATA_WIDTH),
.ADDR_WDITH(ADDR_WDITH)
)readOnly(
.clk (clk),
.rst_n (rst_n),
.cpu_rd (cpu_rd_A), // CPU 发起读请求(高有效)
.cpu_rd_data (o_mibr_to_cpurdata),
.cpu_raddr (a_raddr),
.cpu_wr (), // CPU 发起写请求(高有效)
.cpu_rd_ack (high_to_cpu_ack), // 外设返回的读应答(可以和 wr_ack 共用一个也行)
.cpu_wr_ack (), // 外设返回的写应答
.cpu_timeout () // 超时告警,保持到本次访问结束
);
high_pri #(
.DATA_WIDTH(DATA_WIDTH),
.ADDR_WDITH(ADDR_WDITH)
)mibr(
.clk (clk),
.rst_n (rst_n),
.i_cpu_rd (cpu_rd_A), // CPU 发起读请求(高有效)
.i_cpu_rdata (a_rdata),
.i_cpu_raddr (a_raddr),
.i_cpu_rd_ack (A_rdack_cpu),
.o_cpu_raddr (o_mibr_to_raddr),
.o_cpu_rdata (o_mibr_to_cpurdata),
.o_cpu_rd (high_to_A_rd),
.o_cpu_rd_ack (high_to_cpu_ack)
);
endmodule1、cpu_access 模块,每58拍发起一次读请求,如果超过32拍没有收到ack,则会拉起超时告警,轮询读取A 中的不同地址,ack信号返回后不是立刻拉低rd请求(这个应该做在top里面模拟模块间的pipe比较合理)。
2、high_pri模块,每32拍会发起一次对A模块的读请求,这个请求的优先级高于cpu_access,会保证读数据返回周期是32,读地址也是轮询。

上面是cpu_access的接口数据,下面是high_pri的读上报接口数据。
再看模块内部的状态信息:

hi_period 状态内屏蔽外部的读请求,内部发起读请求,等待ack返回之后,hi_period拉低。在这之后,如果外部有读请求,那么拉起wait_ack信号,不再进入hi_period状态,直到外部请求对应的ack信号返回。
Verilog设计:分优先级的CPU访问接口协议设计
https://songshiyu.cn/archives/verilogshe-ji-fen-you-xian-ji-de-cpufang-wen-jie-kou-xie-yi-she-ji
评论